









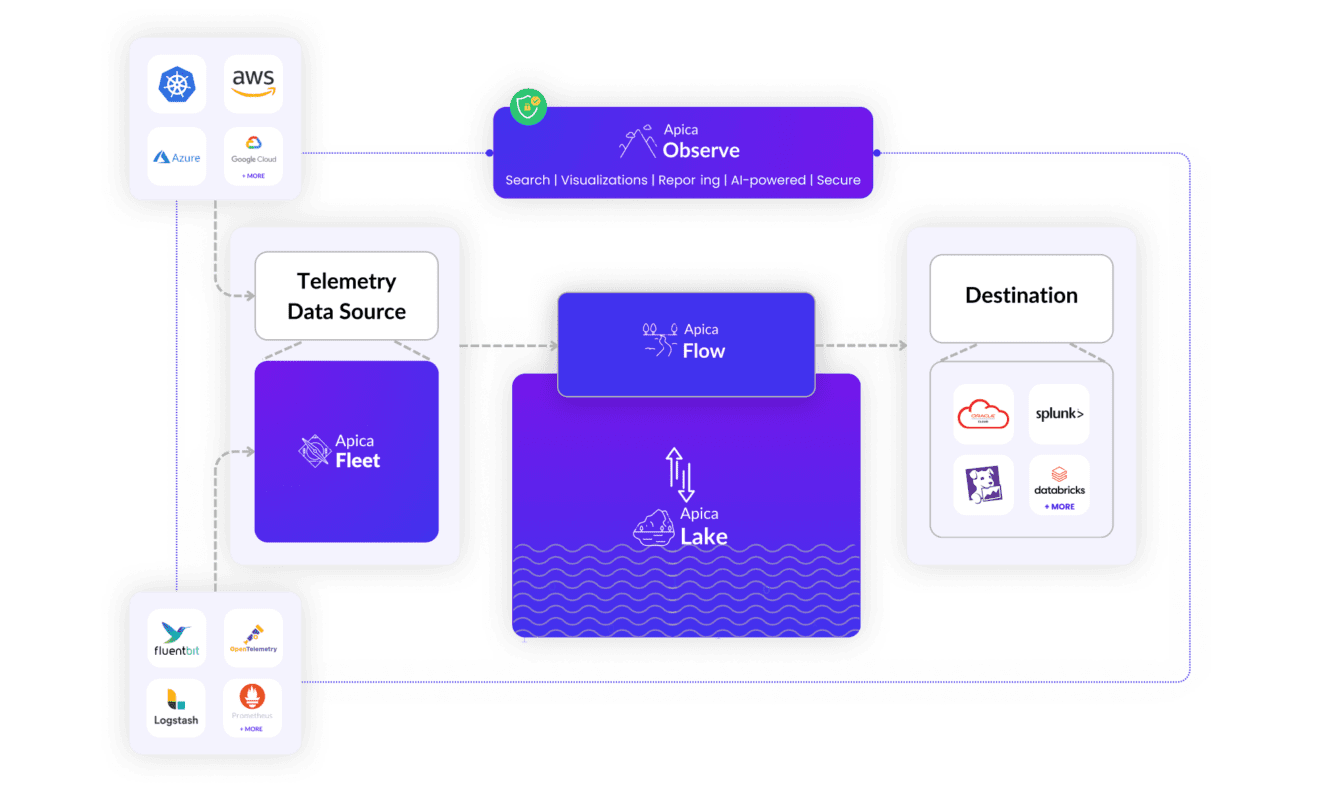

Auto scale-out
Architecture

Decoupled
Infrastructure

Infinite
Compute

Infinite
Storage

Lowest
TCO

Real-time Performance

Fleet
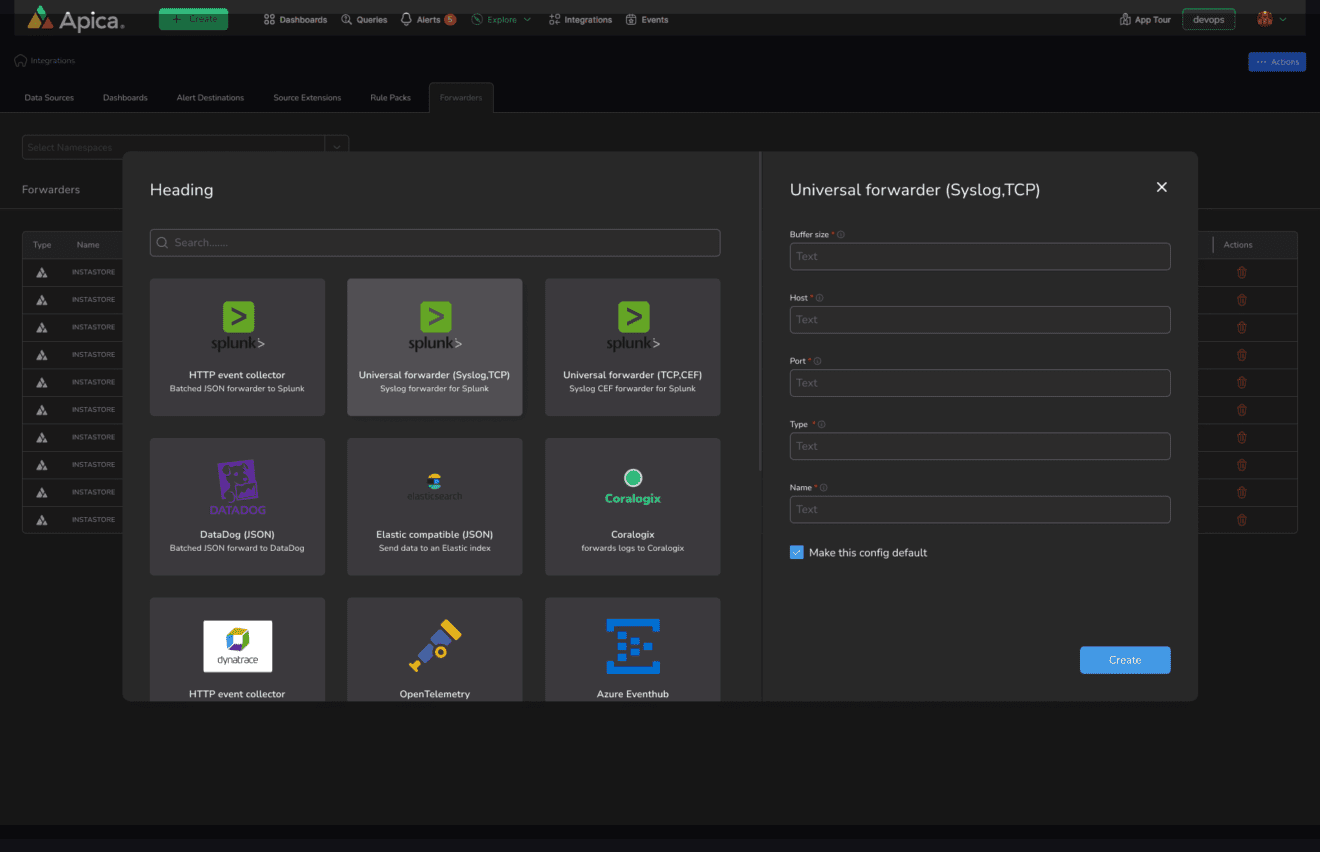
Fleet simplifies telemetry data collection by automating agent deployment and configuration, providing insights into the real-time health and performance of your sprawling infrastructure.
Flow
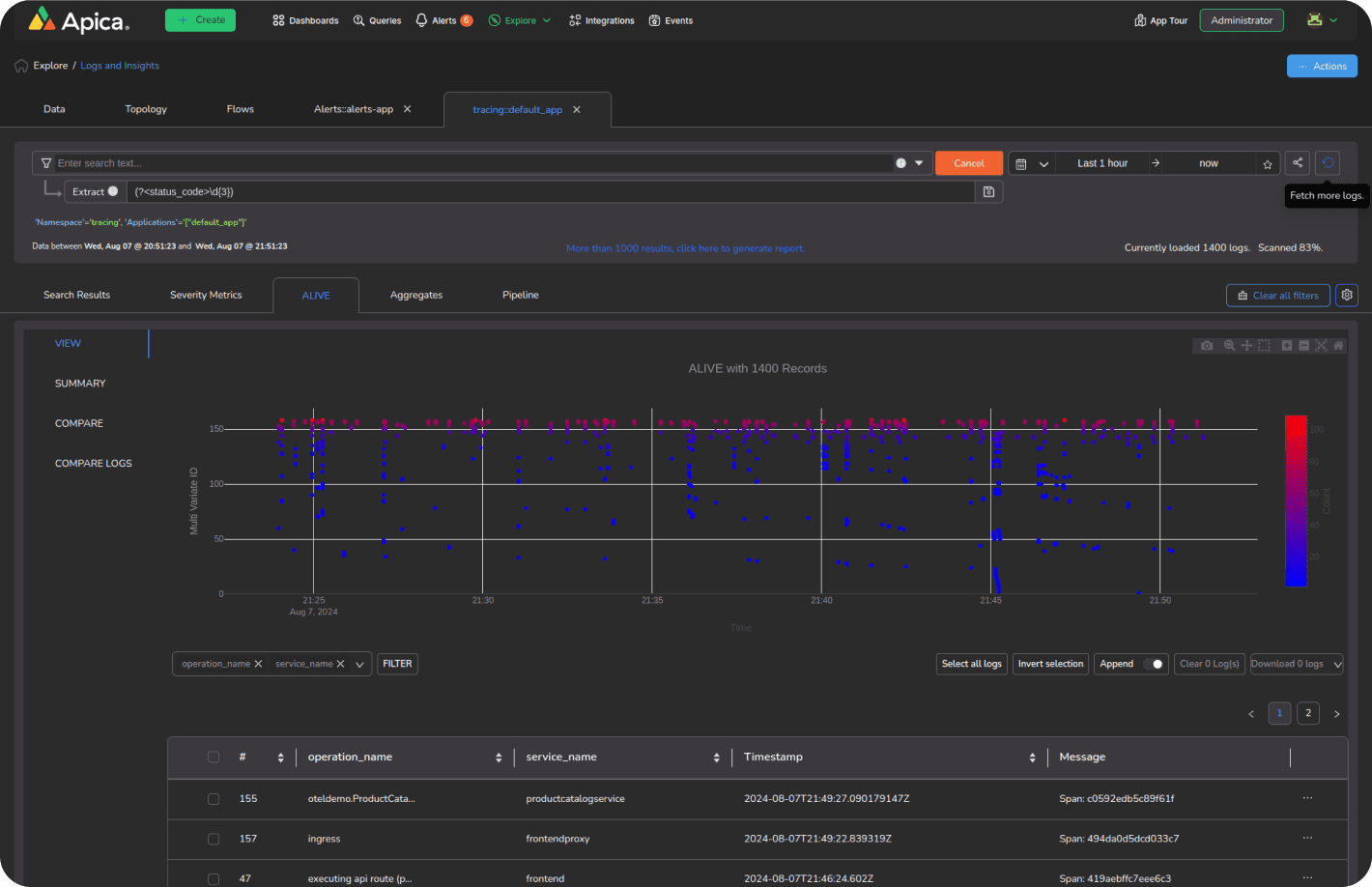
Get decision-ready data in just a few clicks. Take full control of every step in your data journey, from source to destination and back. Cut costs and resolve issues more quickly.
Lake
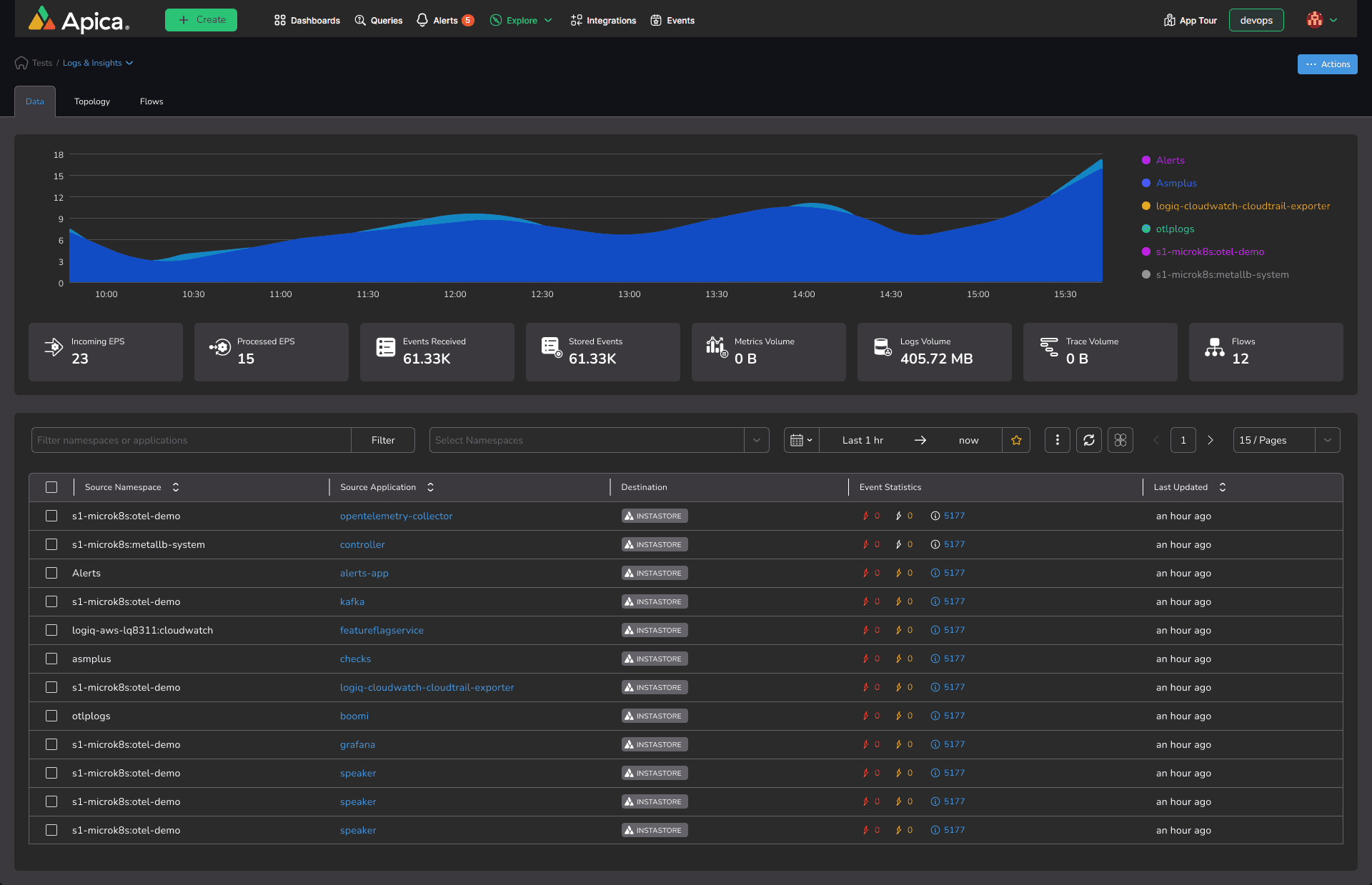
Store and search unlimited operational data with InstaStore—covering business, observability, security, network, etc.—without the performance issues or expenses of conventional data lakes.
Observe
Discover intelligent observability on your terms. Delivering immediate, actionable insights across all data types.