










In the current high-volume business environments, the demand for accurate and available data is higher than ever. Traditional data management solutions often fall short, escalating costs and operational challenges.
Gartner reports that by 2027, at least 40% of organizations will deploy advanced data storage management solutions, a significant increase from just 15% in early 2023. This shift underscores the urgent need for efficient data management tools.
The Challenge
The Solution: Apica Flow
Apica’s Flow is designed to address these challenges head-on. Our modern data management platform reduces data analysis costs and ensures full scalability of your data pipeline. By integrating Flow with your Splunk deployment, you can achieve significant cost savings and operational efficiencies.
Real-Life Business Case: Apica Flow and Splunk
Key Benefits of Apica Flow
Apica Flow offers a slew of benefits:
1. Cost Reduction: Decrease operational data storage costs.
2. Enhanced Telemetry Pipelines: Gain control over data pipelines to avoid vendor lock-in.
3. Seamless Interoperability: Integrate smoothly with Splunk and other observability tools.
4. Adoption of New Technologies: Easily integrate new technologies like OpenTelemetry.
How Apica Flow Works
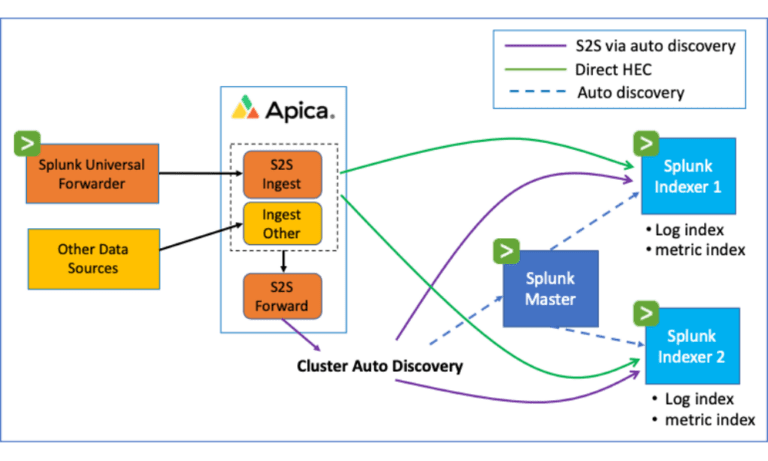
Core Capabilities
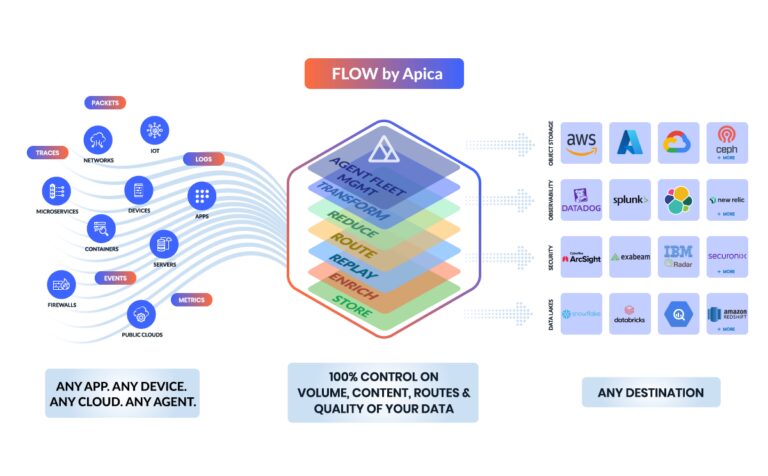
Apica Flow is equipped with several practical features, including:
- Real-Time Optimization: Automatically adjusts the flow of tasks based on real-time data.
- Pipeline Control: Supports multiple data sources and formats, with capabilities for scheduling and automating pipelines.
- Integration: Seamlessly integrates with a range of tools and platforms.
Conclusion
Apica Flow enables enterprises to maximize their use of Splunk while significantly reducing costs. It offers lower licensing and infrastructure costs, 100% data control, and the ability to integrate open-source technologies. Built-in data controls prevent unexpected costs, ensuring a smooth transition to newer technologies.
Ready to economize your Splunk costs? Learn more about how Flow can transform your data management strategy.
Read the full use case here.
